Exact Globe en Exact Synergy koppelen aan Power BI

In dit artikel wil ik jullie meenemen hoe Exact Globe het beste gekoppeld kan worden aan Power BI en welke uitdagingen daar bij komen kijken.
Exact Globe draait op een Windows Server omgeving en maakt gebruikt van een Microsoft SQL database. Om data te laden in Power BI zal deze rechtstreeks uit de database moeten worden geladen. Exact bied geen andere mogelijkheden tot toegang.
Voordat ik de details in ga hoe de Exact gegevens moeten worden ingeladen in Power BI vanuit de database, wil ik jullie eerst meenemen in hoe Exact technisch omgaat met de SQL database. Dit is namelijk belangrijk om te begrijpen. Verkeerd omgaan met de Exact SQL database kan zorgen voor verstoringen in Exact, met mogelijk downtime tot gevolg.
Exact, SQL en Locks
Exact maakt dus gebruik van een SQL database. Elke keer als Exact geopend wordt, als er een venster geopend wordt of als er een actie wordt uitgevoerd leest of schrijft Exact naar de database. Dit zijn vaak wel tientallen queries per keer. Als een query wordt vertraagd door wat voor reden dan ook, kan Exact traag worden of onvoorspelbaar gedrag vertonen. Het is daarom belangrijk dat de database in goede conditie is en dat er goede monitoring plaatsvindt op de SQL database om problemen te voorkomen.
SQL databases zijn gemaakt om 100% betrouwbaar te zijn met betrekking tot de gegevens welke worden getoond. Dit is voornamelijk belangrijk omdat het in het geval van Exact vaak om financiële gegevens gaat. Om deze betrouwbaarheid te borgen kan SQL server maximaal één taak per enig moment uitvoeren op een bepaalde gegevensset. Als er gegevens in de database worden geschreven zal een zoekopdracht even moeten wachten tot de database klaar is met de vorige actie op de betreffende gegevensset*. In de praktijk heeft de eindgebruiker daar minimaal last van omdat het uitvoeren van de zogenaamde queries beperkt tijd in beslag neemt waardoor alle gebruikers op korte termijn aan de beurt komen. Het belang in relatie tot Power BI licht ik later in dit artikel toe.
*SQL Server ondersteundt nog een mode waar dit niet bij op gaat. Deze mode mag niet geactiveerd worden in combinatie met Exact.
Voorbeeld: Kees haalt in Exact een lijst met productieorders op. Op hetzelfde moment wordt er door Sjoerd in Exact productieorders aangemaakt. Indien het aanmaken één seconde duurt zal het laden van de lijst met productieorders voor Kees één seconde langer duren.
De SQL database borgt het lezen en schrijven van data door middel van Locks. Op het moment dat een tabel, of een bepaalde rij, gelezen of beschreven wordt, plaatst SQL een lock op de betreffende data. Met deze Lock is de data niet toegankelijk. Zodra de actie klaar is, wordt de lock weer vrijgegeven en is de data beschikbaar voor de volgende actie.
Naast de automatische Locks, welke worden ingezet voor het lezen en schrijven, is het ook mogelijk om handmatige Locks op gegevens te plaatsen. Exact maakt hier ook gebruik van. Om te voorkomen dat twee verschillende gebruikers bijvoorbeeld tegelijkertijd dezelfde order kunnen aanpassen, heeft Exact er voor gekozen om een Lock in te zetten. Zodra een gebruiker een order opent, zal Exact een lock zetten op deze order. Zodra de tweede gebruiker de order opent zal deze een melding krijgen dat de order niet toegankelijk is. Zodra de eerste gebruiker de order weer afsluit wordt de lock vrijgegeven en kan iemand anders de order openen. Hierdoor kan er gegarandeerd geen gegevensverlies optreden.
Door het werken met de Locks op bijvoorbeeld een productieorder ontstaat er wel een nieuw probleem. De lijst van productieorders kan niet meer opgehaald worden zodra de geopende productieorder een onderdeel is van de betreffende lijst. Gelukkig zit er in de SQL een trucje om de Locks te negeren. In de code voor het ophalen van gegevens wordt er NOLOCK toegevoegd, waardoor in feite tegen de database wordt verteld: Negeer de lock, geef mij de gegevens maar. Exact past daarom ook NOLOCK toe in de code zodat andere gebruikers wel door kunnen blijven werken.
Het gebruik van NOLOCK heeft één nadeel: Het is mogelijk dat onvolledige gegevens worden opgehaald. Voor een productieorderlijst is dit geen probleem. NOLOCK moet nooit worden toegepast wanneer het ophalen van gegevens altijd 100% betrouwbaar moet zijn.
Maar waarom vertel ik jullie over Locks? Dit heeft toch niets te maken met Power BI? Helaas wel. In het productie voorbeeld hierboven ben ik uitgegaan van één seconde vertraging omdat een gebruiker productieorders aan het aanmaken is. Deze vertraging is beperkt doordat in Exact de queries relatief beperkt zijn. Er wordt altijd maar een heel klein deel van de gegevens opgehaald.
In Power BI daarintegen worden geregeld hele tabellen opgehaald. Dit inladen kan bij grote tabellen minuten tot misschien wel een uur duren. Tijdens het ophalen van de tabellen wordt door Power BI geen NOLOCK toegepast waardoor effectief de betreffende tabel wordt gelockt voor Exact. Dit betekent dat op dat moment niemand meer in Exact kan werken. Als dit niet duidelijk is bij de IT-afdeling, kan het zoeken van de oorzaak langer duren dan gewenst. Want vaak blijft het niet bij die één keer data ophalen. Power BI Pro kan tot maximaal acht maal data ophalen per dag. Dat betekent acht keer per dag langdurige locks op de database en daarbij storingen in Exact.
Er zijn gelukkig een aantal oplossingen om toch gegevens in Power BI te laden zonder dat Exact en dus de eindgebruikers daar last van hebben.
Oplossingen
1. Werken met NOLOCK
Zoals al gesteld wordt in dit artikel kan een NOLOCK een oplossing bieden. Ook is er gesteld dat Power BI niet uit zichzelf deze NOLOCK toepast. Gelukkig kan Power BI geforceerd worden om NOLOCK toe te passen.
Om context te geven wat dit betekend, zal ik aan de hand van een voorbeeld hoe Power BI standaard werkt toelichten hoe NOLOCK kan worden toegevoegd.
Een gebruiker wil de financiële mutaties inladen. Deze gegevens staan in GBKMUT. De normale werkwijze (waarbij NOLOCK niet wordt toegepast) in Power BI zal zijn dat de gebruiker verbinding maakt met de database en vervolgens de tabel GBKMUT selecteert. Power BI haalt de eerste 1000 rijen op en toont deze aan de gebruiker. De gebruiker gaat vervolgens in Power Query de kolommen welke niet nodig zijn verwijderen en plaatst een filtering op kolom transtype met waarde "P" "N" of "C". Hierdoor zijn enkel de financiële gegevens zichtbaar.
Op de achtergrond maakt Power BI de SQL-code welke rechtstreeks uitgevoerd wordt op de database. Nadat de gebruiker het rapport klaar heeft wordt deze gepubliceerd naar de Power BI service (cloud) en zal Power BI de SQL-code uitvoeren op de database en enkel de juiste financiële gegevens ontvangen. Doordat de bovenstaande werkwijze niet mogelijk is, wegens het niet kunnen toevoegen van NOLOCK, zal de gebruiker dus zelf de SQL-code moeten schrijven. Hier zijn twee varianten in:
- De gebruiker voert een simpele select uit op de tabel en voert de rest van de transformaties uit in Power Query, of;
- De gebruiker schrijft uitgebreide een SQL-code en gebruikt Power Query minimaal
Optie 1: Simpele SQL
Selecteer "Get data" en vervolgens SQL Server.
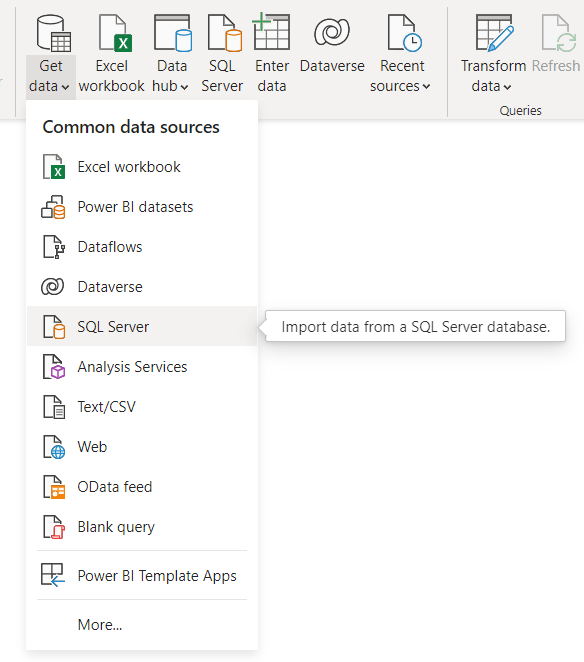
Vul de database gegevens in.
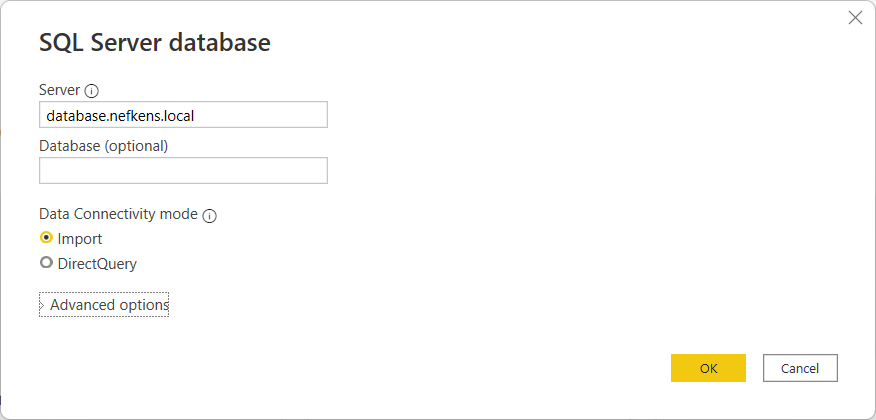
Klap de "Advanced options" open. Hierbij kan de SQL-code geschreven worden. In het geval van GBKMUT zal dit zijn:
Select * from GBKMUT (NOLOCK)Hier staat in feite: Haal alle kolommen (de asterisk) uit GBKMUT. Let hier op de NOLOCK achter GBKMUT. Dit zorgt er dus voor dat een query altijd wordt uitgevoerd.
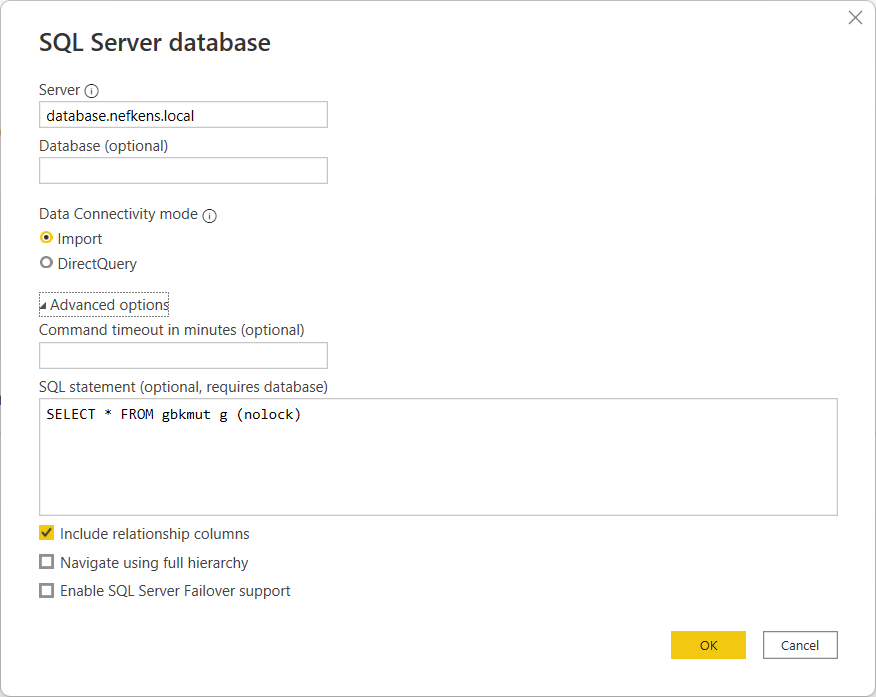
Klik op OK. Indien enkel de financiële gegevens zichtbaar moeten zijn zal de gebruiker de overbodige kolommen verwijderen en een filter plaatsen in Power BI op kolom transtype met waarde "P" "N" of "C".
Het rapport wordt afgemaakt en geüpload naar de Power BI service. Power BI zal het rapport proberen te vernieuwen, wat niet lukt en stopt met een error. Waarom is dat?
Het probleem is namelijk, doordat er reeds een SQL-code is opgegeven zal Power BI niet proberen nieuwe een SQL-code te genereren, maar de transformatiestappen op een hoger niveau uitvoeren. Namelijk op de achtergrond zal Power BI Service geheel GBKMUT gaan ophalen en dit in de cloud zetten, filteren en opnieuw opslaan. GBKMUT is een tabel van vaak vele GB's groot. Dit is te groot om dagelijks te vernieuwen en Power BI loopt er dus op vast. Het resultaat met alleen de financiële gegevens is vele male kleiner waardoor Power BI zonder moeite deze gegevens ophaalt zoals in het standaard voorbeeld. Het kan zelfs zo zijn dat aan het begin alles goed werkt, maar zodra de GBKMUT door de jaren heen groeit de performance steeds slechter wordt. Deze manier van NOLOCK toepassen raad ik daarom ook altijd af.
Optie 2: Uitgebreide SQL
In plaats van de transformaties in Power Query toe te passen zal de gebruiker zelf de hele SQL-code moeten schrijven waarbij de filtering al is uitgevoerd. In dit geval:
SELECT g.datum, g.debnr, g.artcode, g.reknr, g.bkstnr, g.faktuurnr, g.bkstnr_sub as Ordernr, g.bdr_hfl as Bedrag, g.aantal as Aantal
FROM gbkmut g with (nolock)
WHERE g.transtype IN ('P', 'N','C')Dat ziet er zo uit in Power BI:
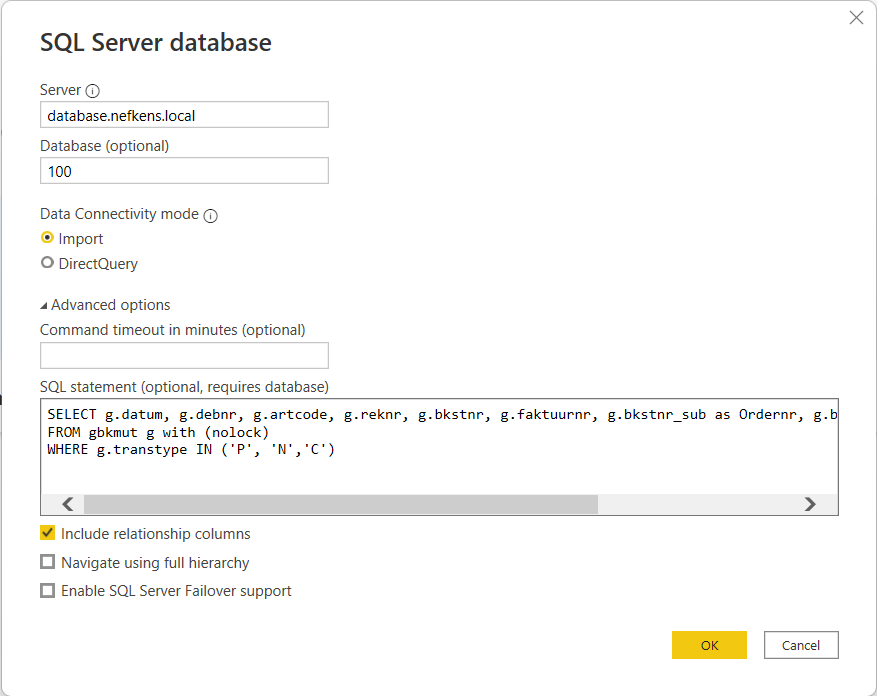
Vervolgens kunnen er in Power Query nog kleine wijzigingen worden uitgevoerd zoals kolommen toevoegen, kolommen hernoemen of type wijzigingen.
Let wel dat hierbij gevorderden kennis nodig is van SQL.
Ideaal is deze oplossing niet. Er blijven veel risico's kleven en de flexibiliteit is ook een stuk minder. Mocht er voor deze oplossing worden gekozen, is het belangrijk dat alleen mensen welke de bovenstaande implicaties snappen en vanuit een AVG alle gegevens in mogen zien, toegang krijgen tot de Exact database. Het moet namelijk ten aller tijden voorkomen worden dat er niet met een NOLOCK wordt gewerkt.
Om toch de rest van de organisatie gebruik te laten maken van de beschikbare data om zelf rapportages te bouwen kan gebruik worden gemaakt van dataflows of datasets welke worden gebouwd op de Exact database, zonder het risico dat collega's de Exact database locken.
Samenvattend:
Voordelen:
- Geen datawarehouse nodig (zie hoofdstuk hieronder)
- Hierdoor alleen Power BI licentie nodig
Nadelen:
- Geen automatische SQL-code (Query Folding).
- Risico op vergeten NOLOCK.
- Kennis nodig van SQL.
- Ook zware queries kunnen merkbaar zijn in Exact, al wordt er gewerkt met NOLOCK.
Bij veel bedrijven wegen de voordelen niet op tegen de nadelen en is het uitgangspunt dat andere applicaties geen toegang krijgen tot de bron database van bijvoorbeeld Exact, maar door gebruik te maken van een data warehouse.
2. Werken met een data warehouse (ProData)
Een data warehouse is in de regel niets anders dan nog een een SQL database naast die van Exact, waarin een deel van de Exact database wordt ingeladen en optioneel getransformeerd naar een meer leesbaarder formaat. De SQL data warehouse kan een lokale database zijn, maar ook een Azure omgeving. Nefkens gaat uit van een Azure omgeving wegens de goede aanwezige ETL tools met betrekking tot het inladen van data.
Een data warehouse heeft nog meer voordelen. In een data-warehouse hoeft namelijk niet enkel Exact data te staan. De warehouse kan dienen om alle relevante bedrijfsgegevens uit de verschillende op één plek onder te brengen in een overzichtelijke structuur zodat iedereen zijn werk kan vormen met relevante gegevens. Data gestuurd werken noemen we dat Een echt informatie gestuurde organisatie waarbij zelfstandige analyses ook mogelijk zijn.
Een data warehouse heeft ook als voordeel dat het kan dienen als Historian. Voorbeeld:
Voordelen:
- Geen risico dat de Exact database negatief wordt geraakt door Locks of slecht performende queries.
- Alle relevante gegevens uit verschillende bedrijfsapplicaties op één plek.
- Alle gegevens al reeds gestructureerd voor BI toepassingen
Nadelen:
- Extra kosten voor het opzetten van een data warehouse.
Conclusie
Power BI is een geweldig pakket om datavisualisaties in te maken. Helaas is de werkelijkheid vaak weerbarstiger. Zodra de gegevens goed zijn gemoduleerd en in Power BI zijn geladen, is het maken van een mooie rapportage en Dashboard vaak nog maar een fluitje van een cent. Maar het proces om daar te komen is vaak nog een hele rit. Daarom hebben we er bij Nefkens voor gekozen daar een standaard oplossing in te bieden. Met ProConnect bieden we een oplossing waarbij het data inladen en moduleren naar een ster schema reeds is uitgevoerd. Met ProData heeft u de data op een veilige locatie zonder het risico dat uw productiedatabase negatief wordt beïnvloed door de databehoefte van uw organisatie. Met ProConnect en ProData kunt u gelijk aan de slag kan met het bouwen van rapportages.